Text Posts
Update: The experiment has been taken down due to Nodejitsu shutting down their free plans. I'll look into reuploading it at some point.
I've been working pretty hard on one of my projects and decided to take a small break and do a little experiment. A while ago (years?), I saw a website that allowed anyone to type anywhere on the screen. I decided to take a couple of hours tonight and recreate it using Node.JS.
My version of the Wall of Text app is available here.
It's built with Node.JS, Socket.IO, and Express (which really was unnecessary, but I was lazy and didn't want to work with the vanilla Node.JS HTTP server). Nodejitsu is providing the hosting.
I'm looking into making it into an infinite canvas, but for now, it extends as far as your screen goes. I suppose if you had a really big screen it would go infinitely... Those with 1080p+ monitors will be able to see beyond those with smaller resolutions. It's sort of an exclusive club if you can see the text on the outskirts of the wall ;)
The wall resets every six hours and shows the number of users connected in the bottom right hand corner of the screen.
tl;dr
See it here.
Around a year and a half ago my Pre-AP English class was assigned a culminating project. This graduation requirement consisted of a 2500 word paper as well as a short presentation. We were prompted to choose a point of contention in the modern world, pose it as a question, gather arguments from debates and other sources, and format it as an essay to convince the reader of a certain position.
I chose, “is technology making us stupider?”
Moore’s Law of the Mind: How Technology is Changing the Way We Think for the Better
In 1965, a computer scientist named Gordon E. Moore wrote that the number of items on a computer circuit would double every year for the next ten, effectively doubling the speed of the computer every 18 months. This principle was called Moore’s Law. He was astoundingly accurate—in fact, his law not only predicted the growth of technology for the ten years after his research paper was written, but for the next 45 as well. Of course, with computers that go faster and faster, come minds that can keep up with them. Not only are we able to process information more quickly than generations ago, but we also have unprecedented access to more information than ever before. However, some critics have recently been speaking out against technology and the Internet, and they pose the question, “Is technology making us smarter or stupider?” Technology is not making the human race stupider– in fact, it is making us much more intelligent, both emotionally and logically. We do rely on technology more–that there is no arguing about–but contrary to the pessimist’s opinion, this is not a bad thing.
Some studies claim to show that technology, particularly the Internet and social networking, is causing the most radical shift in thinking in human history. This is a point that cannot be contested, however some writers and journalists are speaking out because they believe that this is a negative shift. Nicholas Carr, a writer for The Atlantic, is clearly opposed to the way that technology is affecting his brain. He pessimistically states that something “has been tinkering with [his] brain, remapping neural circuitry,” and that his concentration is now shifting while reading (Carr). His article, titled “Is Google Making Us Stupid?”, focuses on his personal experience with the Internet’s brain-melting abilities. He claims that his mind, once able to read entire novels without distraction, is now unable to focus for extended periods of time. Constant distractions, such as email and texting, are the key suspect. Carr quotes Bruce Friedman, a writer, saying “I can’t read War and Peace anymore, I’ve lost the ability to do that. Even a blog post of more than three or four paragraphs is too much to absorb. I skim it” (Carr). A simple search turns up numerous websites with the full text of War and Peace, yet they are littered with advertisements– local coupons, ridiculous savings, and collectible toy soldiers. The same goes for The Atlantic– the article, “Is Google Making Us Stupider?” is available with no hassles online, but it is filled with ads for The Atlantic’s iPad application. Instead of digging through a pile of magazines to find the August 2008 issue in which this article appeared, one can simply sit down at his or her desk and click. Technology takes the burden of going to the bookstore away, but instead replaces it with a web of distraction.
[caption id="attachment_48" align="alignnone" width="300"] "Is Google Making Us Stupid", published in 2008[/caption]
"Is Google Making Us Stupid", published in 2008[/caption]
It’s obvious why these two writers believe that technology is making us stupider: we can’t focus on one thing anymore. We are shifting from one window to the next, from email to the web, from Facebook to Twitter, and from our laptops to our phones. Simply put, we are being overloaded with information. Advertisements, banners, popups, “related articles”– they all point to different, sometimes entirely unrelated pages. Hyperlinks take us from one point to another in the infinite web, and all that information is only a click away. Never before have we been able to jump around so quickly. Nicholas Carr argues that this ability to hop from page to page quickly is bad, but he is simply adapted to a world filled with epic poems and long novels. Our world no longer measures intelligence based on whether you can read, but on our agility and problem solving skills. When one must be able to diagnose a problem with a computer, or even another living creature, it does not matter if you can read War and Peace. However, you must be able to quickly identify the problem and figure out a solution with a high rate of accuracy.
This evolution in speed is also prevalent in the classroom. Recently in one of my classrooms, there was a feud between a student and teacher regarding the existence of centripetal force and its effect on the size of planets. It took the student several minutes to find his physics book, look for the page, and produce an answer. This same information can be found in a minuscule amount of time on the Internet. It took 0.12 seconds for a search engine to find a website with the relevant information– and that was even when the word was misspelled. When corrected, it took the servers under half the time to process the query: 0.05 seconds. After the search results are displayed, one click opens the website. Skimming the Wikipedia article produces the exact same answer in under a minute.
However, not everyone believes the Internet is detrimental to our thinking. To directly combat the August 2008 article in The Atlantic, Carl Zimmer wrote a piece titled “How Google is Making us Smarter.” He cites several studies in which scientists studied how a monkey’s brain reacted to new tools. In this particular experiment a chimpanzee was given a rake. After a while, the chimpanzee’s brain behaved differently– it now responded to the stimuli at the end of the rake and not in the monkey’s hand. This is similar to our reliance on technology: instead of a rake, we have Wikipedia. We have learned to use this Internet tool to work in our environment and react accordingly. GPS is another perfect example– it helps our natural path finding skills and it extends them beyond natural capabilities.
The Internet is synonymous with technology. Arguably, it is one of the most important advancements in all of human history. In an Intelligence Squared Asia debate held in the Hong Kong Convention Center, a battle took place between Thomas Crampton and Jeremy O’Grady (both prominent Internet bloggers), versus Jimmy Wales (the founder of Wikipedia) and Kaiser Kuo with the latter group arguing against the notion that “the Internet is making us stupid.” Thomas Crampton spoke first and argued that humans have progressed from the era of survival, to the era of books, and now we have reached the era of distractions. In addition, he argues that only books, not video games or movies, create a strong tie between oneself and the characters within. This is entirely untrue– all three mediums create a link between the character and the individual interacting with the piece, just at different levels and in different ways. Whether it be watching, playing, or reading, there is always a potential to bond with the characters, and in fact even stronger bonds may be created with multiple ties.
Kaiser Kuo combatted Crampton’s cynical views with a more positive one—while he acknowledged distractions in our lives, he points out the incredible new interactions between humans. New technologies are emerging that allow us to interact across the globe. Everything from Google Documents Collaboration, which provides the ability for 50 people to edit the same document at the same time, to group video chatting, increases our ability to interact with new people. What once was a slow volley of letters back and forth across the ocean is now a real-time chat with business partners in Japan. He also makes a very important point: “intelligence” today is much different from that of the past. He says that the “ability to rapidly assimilate and contextualize inputs of information” and the ability to rapidly decide whether information is worth reading or not is important in the age of technology (O’Grady). All of these distractions may affect you negatively at first, but ultimately the advertisements train humans to pick and choose from a pile of mostly-useless information. “Distraction is something rather new to us,” Kuo says. “It is a cognitive skill set we are still in the process of developing” (O’Grady). The new generation of technology “natives,” those born directly into the world of computers, is the first to experience this new challenge. Kuo jokingly calls the debate audience, a room full of adults, “digital immigrants” in this new world. One of the main issues with the research today is that it is performed on adults who have lived half of their lives reading books and watching simplistic TV shows as opposed to growing up interacting with the digital sphere.
In Everything Bad is Good For You, author Steven Johnson specifically focuses on the evolution of TV. He describes TV as a medium with multiple threads, or individual story lines. For example, in the TV show 24, there are a multitude of different and concurrent threads ranging from a terrorist bomb plot to the relationships between characters. However, things weren’t always this complex– Starsky and Hutch (1975-1979) and Dragnet (1951-1959) had very linear plot lines to cater to the average intelligence of the time. These shows had one narrative, and one narrative only– no side stories, no complex relationships, and very few plot twists. Hill Street Blues is an example provided by Johnson for one of the first multithreaded TV shows. In fact, he states that the 1980 pilot episode of Hill Street actually caused viewers to complain due to the multithreaded nature. Yet today these show pales in comparison to modern TV or mind-bending movies such as Inception. Over the years, TV, movies, and games have trained our minds to handle increasingly complex narratives. "We no longer clamor for simplicity, we want to be surprised, confused, and thrilled with the most complex stories we can get—we just need more."

Back in the Intelligence Squared debate, Jimmy Wales, the founder of Wikipedia, argued against the statement “the Internet is making us stupid.” He said that the developing world, which is gaining access to the Internet for the first time, and the “digital immigrants” are both becoming smarter due to the Internet. The new wealth of knowledge that increases their understanding of the world is extremely beneficial to their culture. Wales used a modern context in this debate: “what would this discussion look like at Wikipedia?” he asked. On the Wikipedia Discussion pages, Wale said that you would see a community of “very thoughtful debate, discussion, dissection,” asking questions that go beyond the surface of the main subject of the article. He claims that they are “trying to understand the world in new ways,” and that this is something that you see across the entire Internet, not just on Wikipedia. This new era of discussion and dissection greatly contrasts the history of Wikipedia’s content. Teachers stereotypically denounce Wikipedia for its “inaccurate content,” however this is often not true anymore. While Wikipedia’s initial articles were filled with bias and inaccurate information, it has become an astounding new source of knowledge. Information is now crowd sourced, and checked by hundreds, if not thousands of eyes.
Wales also used the Flynn Effect to demonstrate an increase in intelligence globally. Jokingly, he said, “you should look up the article on Wikipedia, it’s a great article.” An IQ test is based on the average intelligence of the world. At any one time, the average IQ for the current test is 100 and there is a standard deviation of 15 points. However, James R. Flynn discovered that when participants took an older test, their IQ was measured to be above 100 points consistently. In other words, we are getting smarter—about 3 points per decade, according to Wales (O’Grady). He attributes this change to the changing culture: TV, radio, the Internet—all helping us understand more complex subjects and interact with each other in new ways. In addition, Wales acknowledges an interesting phenomena with a test used to predict Alzheimer’s. These tests, administered to those around 70 years old, predict Alzheimer’s in individuals by testing basic functions, recognition, and skills. However, recently these tests have become invalid– the 70-year-olds of today are consistently outperforming those that took the test 30 years ago. They are getting smarter, and the tests are losing their validity due to the huge margin (O’Grady). The demographic of people who use computers, and even books, is expanding to older age groups, and because of the increased complexity of plot lines and functionality of technology, humans are becoming smarter, and are able to understand more, quicker.
After the debate, William Wong participated in the Q&A session by asking the question, “What kind of intelligence are we talking about? Intellectual capacity, or emotional intelligence?” (O’Grady) By emotional intelligence, Wong is referring to the capacity for humans to connect and interact. As stated earlier, the ability for the Internet to connect is amazing. During the debate, Wales also spoke of a town in the Dominican Republic, which lacked electricity three years prior to his visit. However, a computer lab was recently erected and the people of the town were beginning to use it for the first time. They were discovering YouTube, email, social networking sites– all things that they didn’t had access to only a few years ago. This town, isolated by poverty, is now able to participate in a global discussion.
Intelligence and the word “smart” mean much more than simple book smarts. The word smart not only encompasses the ability to retain knowledge, but mental alertness and resourcefulness. Mental alertness is especially important when browsing the Internet– the human brain is actively scanning bits of information to find the most useful piece. Resourcefulness also comes into play here. We are also busy running through potential sources in our minds, debating whether to trust a news article or to ignore it. This is true in classrooms, for example, when teachers ask their students to search through the databases provided by the school versus someone’s inaccurate GeoCities page. Intelligence is the ability to comprehend, understand, and profit from experience, according to Princeton. Intelligence is obviously applicable to technology and the Internet as read more and more. Long before the Internet, news was consumed through a paper rolled up in your driveway. Now humans are able to browse through a virtually infinite mountain of articles, journals, and blogs.
Ultimately, the Internet and technology are new frontiers that are constantly expanding. Though filled with distractions, the World Wide Web is a training ground that teaches the mind to navigate through the unrelated and find the important. To say that technology is making us “stupid” is absurd– it is untrue, and the statement generalized. When authors claim that the Internet is making “us” stupid they rely on personal experiences, and often they are not well adapted to the changing medium. These “digital immigrants” claim that they can no longer read War and Peace cover to cover, but times are changing. No longer is intelligence measured by your ability to read a 1000 page book, but by your interactions with the digital world around you and your capacity to share and explore the World Wide Web.
PDF and Sources
This entire essay, along with the Works Cited, is available in PDF form as well.
Dedicated to my Pre-AP English teacher, who unfortunately passed away this last winter.
Recently I read a Node.JS framework roundup on OCDevel comparing Derby.JS, Meteor, SocketStream, TowerJS, and Express. The author expressed preference for Derby.JS, but I’m not 100% convinced that is really the best choice.
Don’t get me wrong– I think Derby.js is a fantastic (start) of a framework, and I would love to be able to use it, but I can’t for one simple, but big, reason. It’s no where near production ready.
Sadly, that seems to be the story of Node.JS and the frameworks that use it. Derby, Meteor, SocketStream– they all are relatively new and immature, and in some cases, lack critical functionality of a web framework or have serious issues with security. That sort of puts me, as a developer, in an odd position. I’ve determined Node.JS is a good platform for a project, but without reinventing the wheel, what framework do I use to speed up development?
Node.JS itself is still not even 1.0 yet and definitely isn’t API stable, but it does have a sort of maturity that some of the frameworks do not, which is why I have taken the risk to use Node.JS in production.
While I haven’t used TowerJS or SocketStream, I can get into more detail with the other three frameworks–
Derby.js
I want to use Derby so badly. It looks amazing and the demos are impressive. Imagine writing tens of lines of code or less and being able to publish an app that synchronizes a text box, or even an entire chat log, across multiple clients and in real time. With Derby, you can do that.
So, why don’t I use it? Simply because it lacks so many features and documentation. Every time I do a Google search, I get results about the Derby database (unfortunate naming coincidence) unless I remember to search for “Derby.js” instead. StackOverflow tells the same story– you get minimal help and very few questions pertain to Derby.
Anyways, one really cool feature of Derby is its ability to render your page before it serves it to the browser, so there is no “flash” of a blank page before Javascript on the client side kicks in. Oh, and it works with Javascript disabled and for web crawlers and indexers.
But Derby lacks sessions and authentication. Or maybe it does have them. Who knows? I can’t find any documentation on either. (Yes, I know authentication’s coming in Racer, but I’m not exactly sure about the sessions, and no one seems to have documented it well outside of Racer’s GitHub repository). On the up side, Derby.js is by the same guy who wrote Everyauth. If that’s the case, why it hasn’t already been implemented is beyond me.
Anyways, that brings me to a Pro-Con list:
Pros
- Real time, syncs models across client and server
- Code sharing for client and server
Cons
- Slow progress due to small number of followers and contributors
- No authentication or sessions, as far as I can tell
- Unstable, not usable for production
Recommendation
Do not use it for anything other than experiments, demos, and messing around. It’s not quite mature enough to use in production web apps. I’m looking forward to seeing where it goes, but it seems to have been at version 0.3.12 for a while now…
Meteor
Meteor is very much like Derby.JS. It handles the realtime synchronization of models across the client and server and allows for code sharing. The demos are equally impressive, and show off exactly how you can build real time games with Meteor.
But the same issues as Derby apply, and there are some pretty weird hacks that they used for workarounds (v0.3.9). Like Derby, there’s no authentication.
In bright red in their documentation is this:
Currently the client is given full write access to the collection. They can execute arbitrary Mongo update commands. Once we build authentication, you will be able to limit the client’s direct access to insert, update, and remove. We are also considering validators and other ORM-like functionality.
Since you are basically exposing your server side database to the client, I can come along and run Users.remove({}) and your entire users catalog has been erased. This will be addressed in the future– they are already working on an implementation.
That alone should scare you off from using Meteor in production, which is too bad, because like Derby, Meteor looks promising.
Depending on your preferences, you may also want to shy away from Meteor due to it’s use of Fibers instead of Node’s traditional callback-style programming, which Derby does use.
Also unlike Derby, Meteor does not render your content server side. This means search engines cannot index your content (which may not be an issue if your app’s a chatroom or app) and Javascript must be enabled. Meteor claims to have a fix in v0.3.9, but it’s such a bad workaround it’s not worth using. Essentially, they spawn an entire headless browser any time a web spider crawls your page. Let me say that again– Meteor’s workaround to prerender the page is to launch an entire web browser on your server, render the page, then pass that to the search engine. It’s extremely ineffecient and makes you prone to a DDOS attack.
Pros
- Real time synchronization of models
- Session support
Cons
- Direct Mongo access
- Uses a proprietary package manager (i.e. not NPM)
- Terrible implementation of server side rendering
But hey, they have $11M in funding, so it can only get better. I hope. At least for Andreessen Horowitz’s sake.
Recommendation
As with Derby, do not use it for production. It’s still maturing and lacks authentication support as well. Plus, even worse, anyone can come along and erase your entire database in one command from their web inspector. But the demos are cool, and it looks like progress is being made more rapidly than Derby.
Express
This is the only framework I’ve ever used in a production Node.JS app. They’re on version 3.0 and the framework is quite mature. But unlike Derby or Meteor, it isn’t real time. If you ran a website on Express, your visitor wouldn’t be able to tell the difference between a PHP app and Express– which might not be a bad thing, depending on what you’re making.
It’s pretty simple to use in that you define a path for Express to handle and then assign a function to it. It works with the Jade templating engine out of the box, but you can use other stuff too.
One big thing to note is that Express is not an MV* framework. In fact, there’s no models anywhere in Express. You have to build those yourself with something like Mongoose or whatever.
As the OCDevel post mentioned, Express is more of a DIY framework. It handles the important stuff like URL routing and even templating, but data and user management is up to you. Want authentication? Drop in a package like everyauth and set it up using Express’s middleware. The framework is so popular, most packages I’ve seen have support for it. So while there’s no built in support for a lot of things, you can usually find a package built to work with Express that handles what you need.
Pros
- Easy to use and setup
- Handles the important stuff, leaves the rest to you
- RESTful– no real time stuff
- Not MV*
Cons
- Handles the important stuff, leaves the rest to you
- RESTful
- Not MV*
Recommendation
Unlike the other two frameworks, Express is a little more ambiguous in its pros and cons. What I may consider a pro (not MV), someone else may hate. But if Express looks like something you could use and deal with, you can* use it in production. It’s pretty stable and popular, so you’ll get a fair amount of support.
The Future
I’m looking forward to seeing Derby.js and Meteor mature, but for now, they just aren’t stable. I’d definitely be curious to see how TowerJS works, but there’s just so much CoffeeScript (which I hate, personally). I have used Express in production, it works beautifully, and I’ll continue to do so in the future (I have another two projects using it in development) because it’s mature, so of course I’m biased.
You’re probably wondering why I’m plugging for maturity and using Node.JS, which is still on version 0.8.x and not exactly stable. So I have a double standard, but Node.JS is relatively stable and feature complete compared to the frameworks that run on top of it. And I do still use a traditional PHP/MySQL approach for applications that don’t necessarily need Node.JS, but PHP is a terrible language for certain tasks.
In any case, only time and active development will help these frameworks along. Like I said, I have some projects that I want to use Derby.js for– but its immaturity and inability to do simple things such as authenticate a user (and the difficulty of building/integrating it yourself) makes it a bad choice.
The state of frameworks and Node.JS is kind of odd, but hopefully it’ll improve over time.
Around eight years ago, I sat down at the computer for the first time as a programmer. Little did I know, the simple, tacky website I built was the first step towards the person I am today.
I still remember the two paned, frame based website I built. It was terrible, with solid yellow backgrounds, and existed solely to show off photos of my new dog. This was back in the day when Microsoft FrontPage still ruled. During the winter, I made snowflakes drift down the page slowly using Javascript snippets from various websites, and during a power outage one year I built a Flash version of the site that mirrored my dark house with only virtual candle to light up the content. Really, everything I made or did was seen by a handful of people that landed on my site from a Google query. And I still have no clue exactly what they searched to get there.
Recently, on a website called Forrst, someone posted a question: “how did you all get in the position that you all are in?”
For me, it wasn’t just a passion for computers that improved my skills beyond the solid yellow backgrounds and tacky Javascript effects. It was the years and years of building useless side projects.
It’s not as Useless as it Seems
Over my years as a programmer, I’ve built tens of tools, websites, apps, and miscellaneous scripts– but there are only a handful that made it into the public. I have a habit of practicing and learning by building small tools or apps. It started out as citation generators (for school papers), and has more recently been small Node.js experiments. Almost every single one of these experiments has been done before by someone else. I wasn’t building a revolutionary new product– in reality, I was reinventing the wheel. I almost never added unique functionality, just recreated it.
But it was never as useless as it seemed. There have been times where someone has asked me, “what are you working on?” “Nothing,” I would reply. And I meant it– in their eyes, I was working on nothing. Just some website that I’d half finish and burry in my tangled mass of Dropbox folders. Yet I’ve learned many new techniques, such as how to built hierarchical menus using recursion, how to use Cron jobs effectively to scrape websites, and how to work with new languages and platforms. As long as you do not cheat yourself and copy and paste code from another implementation, anything you build is practice. That isn’t to say you need to avoid all libraries and plugins– sometimes it isn’t your goal to recreate the Sizzle CSS selector engine or WebKit. Just ensure you are using your time to learn something.
Looking back, it’s actually pretty astounding what I’ve built.
- A deal aggregator that notifies you when a watched item goes below a certain price or has a sale percentage
- 4-5 different website templates for my personal portfolio
- 2-3 different weather apps, across iOS and mobile web
- AWS Server management app for the iPhone, which is fully functional for managing EC2 servers and elastic IP addresses, as well as partial support for managing EBS volumes and S3
- A time management app for high school and college kids, incorporating a flash card sub-app
- And even more random web-apps that I can’t even find anymore
And yet, all of this stuff has never been seen by anyone else. In fact, until now, no one else has even known about most of these random projects.
Why Not Release Them?
A lot of people call me crazy for simply discarding these projects. They claim it’s a waste of time, a waste of resources, and potentially a waste of a good idea. And they might be right– at least about the wasted opportunity for one of those ideas to actually be a hit and make some money.
But I don’t have unlimited time or resources, and I can’t launch every experiment I make. But, Andrew, “Why don’t you just spend less time on the little ideas, and focus on the few good products that have some potential?”
We can all agree a basic MLA citation generator written in C# would be almost completely useless. If anything, it might be useful to open source it or write a tutorial on it to help others, but this particular example was well before I had any knowledge of version control or the capacity to write a blog post.
But the deal aggregator– that might have some use. After all, I regularly browse deal sites myself, and I hate receiving tens of emails from tens of different deal websites. Others must want this product, too. The problem was, it worked– but only for myself. It was hacked together as an experiment in RSS parsing and Regex, but it was never meant to support hundreds or even thousands of users looking for deals on the newest Macbook Air. I would have to spend even more time building additional features (such as basic user authentication), and then polish the app. After all, there isn’t much of a point to launching half-baked products that I have to support.
Ultimately, the point of these experiments wasn’t to launch them to the public– it was to launch them for myself. I actually used these apps to a certain extent. The MLA citation generator helped me through school until the district got a subscription to Noodle Tools, and the deal aggregator actually did end up notifying me of a few deals. But even more importantly, they taught me a valuable lesson– build something that others see as useless, as long as you see a point to it and can learn something from it.
Recently, there was a flurry of tweets that appeared on my Twitter timeline talking about Derby.js. I’ve never used a framework that did so much for you– realtime synchronization of the client and server. Essentially, this enables one to write an application in which two users edit the same text field–live–without writing too much code yourself. Derby handles all of the synchronization of the models and views. Think Google Docs collaborative editing.
That’s great, but after further investigation, it seems like Derby.js isn’t quite as mature as I’d like– it’s not 1.0 yet. To be fair, neither is Node.js (the platform behind Derby) or Meteor, but there seems to be quite a bit missing from Derby. For example, as far as I can tell, there’s no easy way to handle sessions. This may be a result of a lack of documentation, but it appears that the developers behind Derby are working on authentication at this moment. If anyone has writeup on how to handle sessions in Derby, I’d live to hear about it.
The one framework I always see compared to Derby.js is called Meteor. Similar to Derby, it handles things such as updating views live across multiple clients, though Meteor does it somewhat differently. While Derby is designed to be easier to use with different types of database systems, Meteor works closely with MongoDB. In fact, the client API for accessing the database is almost exactly like what you’d expect on the server-side with something like Mongoose.
While there are some drawbacks and controversies surrounding the framework (see Fibers vs Callbacks), Meteor looks like a pretty interesting option when creating an app that requires realtime feedback. Personally, I’m more attracted to the traditional callback style of programming of Derby, but the lack of robust documentation and a large developer community behind it is a huge blow to Derby’s usefulness. This will change over time, but at a much slower rate than Meteor, which recently received $11M+ in funding. This financial backing ensures that Meteor will remain around and supported, and for developers who need a financially and developmentally stable framework, the funding will only make Meteor more appealing.
Today, I want to go over how to create a really simple Meteor app. Essentially, this is a writeup for Tom's Vimeo screencast. One major difference between my writeup and Tom's video tutorial is the way we handle events in Meteor. Rather than copying and pasting code from one of Meteor's examples, I take you step by step through a custom implementation of handling the enter key press to submit a message. Let's begin!
Creating a Meteor App
One big plus of both Derby and Meteor is their respective command line tools. Unlike Derby, which uses Node’s native NPM tool, Meteor comes with its own installer.
From the terminal (on Mac OS X and Linux), run the following command. Ensure you already have Node installed.
$ curl https://install.meteor.com | /bin/sh
Meteor will do its thing, and install the command line tools.
To create a project, navigate to a directory and run the following command. This will create a subfolder and populate it with Meteor and a basic template for a realtime app.
$ meteor create chat
Now, you can run the app from the terminal. Simple navigate to the proper directory and run meteor.
$ cd chat
$ meteor
Running on: http://localhost:3000/
To see the template app, open any modern web browser and navigate to http://localhost:3000/.
If you want, you can even deploy it to Meteor’s own servers using the built in meteor deploy command.
$ meteor deploy my-app-name.meteor.com
You can leave the app running, since all browsers connected to it will update live once you save your code.
Developing the Chat App
In the folder generated by the meteor create command, you can see several different files. Depending on whether you have the ability to view hidden files, you may also see a .meteor folder. This folder contains Meteor itself, along with the MongoDB database file.
In the root folder for your app, you should see chat.html, chat.css, and chat.js. These three files should be self explanatory. The HTML file contains the templates and views for the app, both styled by chat.css. The Javascript file contains the scripts run on both the client and the server. This is important– do not put anything, such as configuration data and passwords, in this script since anyone can see it by viewing the source of your application.
Open the chat.js file in your favorite text editor. Personally, I use Sublime Text 2 for its simplicity and multi-cursor features.
You can see the following code in the chat.js file.
if (Meteor.is_client) {
Template.hello.greeting = function () {
return "Welcome to chat.";
};
Template.hello.events = {
'click input' : function () {
// template data, if any, is available in 'this'
if (typeof console !== 'undefined')
console.log("You pressed the button");
}
};
}
if (Meteor.is_server) {
Meteor.startup(function () {
// code to run on server at startup
});
}
Notice the Meteor.is_client and Meteor.is_server portions of the code inside of the if statements. Code inside of these blocks will only be run if the executing computer is a client or server, respectively. This demonstrates the code sharing abilities of Meteor in action.
Delete all of the code inside of the if(Meteor.is_client) statement and the entire Meteor.is_server if statement so you are left with the following.
if (Meteor.is_client) {
}
Notice, once you save the script file, your browser will immediately refresh and load the new script.
Creating the View
Before we modify the script file, the view that will show the chat log needs to be created.
Open the chat.html file in your text editor and delete the code in the body tag, as well as the template with the name of “hello”. Your code should look like the following.
<head>
<title>chat</title>
</head>
<body>
</body>
Inside of the body tag, add the following.
{{> entryfield}}
Meteor uses a template system very similar to Mustache. The curly braces (mustaches– get it?) denote an action for the template system to perform. By simply typing a word in between two sets of mustaches ({{hello}}), the template system will replace that code with the variable hello. More on that later.
See how there is a greater than symbol (>) before the word “entryfield”? That designates for Meteor to render a template.
To create the template named “entryfield”, add the following below the body tag.
<template name="entryfield">
<input type="text" id="name" placeholder="Name" /> <input type="text" id="message" placeholder="Your Message" />
</template>
The template tag has a single attribute in this case– the name of the template. This is what we use when rendering the template. Notice how the name of the template is the same as the code we inserted into the body ({{> entryfield}}).
If you look at your web browser, you can now see that it has refreshed and the inputs are being displayed.
Next, add in another mustache tag into the body to render the list of messages.
{{> messages}}
Finally, we need to create the template named “messages”. Copy and paste the following below the “entryfield” template.
<template name="messages">
<p>
{{#each messages}}
<strong>{{name}}</strong>- {{message}}
{{/each}}
</p>
</template>
Notice the each clause. In Meteor, you can loop over an array in a template using the following syntax.
{{#each [name of array]}}
{{/each}}
Inside of this each loop, the context changes. Now, when referencing variables, you are referencing properties of each array element.
For example, in our chat app, we are looping over “each” of the elements in the array named “messages”. This array will look like the following.
[
{
"name": "Andrew",
"message": "Hello world!"
},
{
"name": "Bob",
"message": "Hey, Andrew!""
}
]
Inside of the each loop, you can see {{message}} and {{name}} being referenced. These will be replaced with the properties of each of the elements of the messages array (Andrew and Bob for the name, and the respective Hello messages).
Back in your web browser, you should see no change. This is because the messages array has not been passed to the template yet, so Meteor is looping over and displaying nothing.
Your final chat.html file should look like the following.
<head>
<title>chat</title>
</head>
<body>
{{> entryfield}}
{{> messages}}
</body>
<template name="entryfield">
<input type="text" id="name" placeholder="Name" /> <input type="text" id="message" placeholder="Your Message" />
</template>
<template name="messages">
<p>
{{#each messages}}
<strong>{{name}}</strong>- {{message}}<br/>
{{/each}}
</p>
</template>
The Javascript
For now, most of what we will deal with is client-side code, so all code provided below goes within the Meteor.is_client if code block unless stated otherwise.
Before we actually write the code that displays the messages, we have to create a “Collection”. Essentially, this is a group of Models. In other words, in context of the chat app, the Messages collection will hold the entire chat log, and each individual message is a Model.
Before the if statement, add the following code to initialize the Collection.
Messages = new Meteor.Collection('messages');
This goes outside of the client-only code block because we want this Collection to be created for both the client and server.
Displaying the chat log is very easy since Meteor does most of the work for us. Simply add the following code inside of the if statement.
Template.messages.messages = function(){
return Messages.find({}, { sort: { time: -1 }});
}
Let’s break it down–
Template.messages.messages = function(){ … }
The first section (Template) indicates that we are modifying the behavior of a template.
Template.messages.messages = function(){ … }
This second part indicates the name of the template. For example if we wanted to do something to the “entryfields” template, we would change the code to Template.entryfields.variable = function(){ … }. (Don’t do this now.)
Template.messages.messages = function(){ … }
Finally, the third section represents a variable in the template. Remember how we included an each loop that iterated over the messages variable? This is how we specify what messages really is.
If you go to your web browser, you will see that nothing has changed. This is still expected because while you are now fetching the messages, there are no messages to actually display.
Your chat.js file should look like this. It’s amazing that this is all of the code we need to display a real time log of chat messages on the server.
Messages = new Meteor.Collection('messages');
if (Meteor.is_client) {
Template.messages.messages = function(){
return Messages.find({}, { sort: { time: -1 }});
}
}
Adding a Message through the Console
This part is optional, though it can be helpful for debugging. If you just want to skip it and learn how to make the entry form react to key presses and such, continue below.
If you want to test your message display code, you can manually insert a record into the database. Open up your web console in your browser and type the following.
Messages.insert({ name: 'Andrew', message: 'Hello world!', time: 0 })
This creates a record in the database. If you did everything correctly, the message should also show up on the page.
The Message Entry Form
Back in the chat.js file, we are going to link the input form to the database to allow users to submit chat messages.
Add the following code at the bottom, but within, the if statement.
Template.entryfield.events = {
"keydown #message": function(event){
if(event.which == 13){
// Submit the form
var name = document.getElementById('name');
var message = document.getElementById('message');
if(name.value != '' && message.value != ''){
Messages.insert({
name: name.value,
message: message.value,
time: Date.now()
});
name.value = '';
message.value = '';
}
}
}
}
This is a lot, so let’s go through it. As you might recall, the second property after the word Template defines which template we are modifying. Unlike before, where we were setting up code binding the database to the “messages” template, we are modifying the “entryfield” template.
The events property of the template contains an object with its keys in the following format.
"[eventname] [selector]"
For example, if we wanted to bind a function to the click event of a button with the ID of hello, we would add the following to the events object.
"click #hello": function(event){ … }
In our case, we are binding a function to the keydown event of the field with the ID of message. If you remember, this was set up earlier in the tutorial when we created our template in the chat.html file.
In the events object, each key has a function as its value. This function is executed with the event object passed as the first parameter when the event is called. In our chat app, every time any key is pressed (keydown) in the input field with the ID of “message”, the function is called.
The code within the function is fairly simple. First, we detect if the enter key was pressed (enter has a key code of 13). Second, we get the DOM elements of the two input fields by their IDs. Third, we check and ensure that the input values are not blank to prevent users from submitting a blank name or message.
It’s important to notice the following code. This is what inserts the message into the database.
Messages.insert({
name: name.value,
message: message.value,
time: Date.now()
});
As you can see, this is similar to the code we inserted into the console, but instead of hard coding the values, we use the DOM elements' values. Additionally, we are adding the current time to ensure that the chat log is properly ordered by time.
Finally, we simply set the value of the two inputs to ‘’ to blank out the fields.
Now, if you go into your browser, you can try and input a name and message into the two input fields. After pressing enter, the input fields should be cleared and a new message should appear right under your input fields. Open up another browser window and navigate to the same URL (http://localhost:3000/). Try typing in another message, and
As you can see, Meteor is pretty powerful. Without writing a single line of code to explicitly update the message log, new messages appear and are synced across multiple browsers and clients.
Conclusion
While Meteor is pretty cool to work with and there are some pretty useful applications for it, like Derby.js, it is immature. For examples of this, just browse through the documentation and look for the red quotations. For example, the documentation states the following about MongoDB collections:
Currently the client is given full write access to the collection. They can execute arbitrary Mongo update commands. Once we build authentication, you will be able to limit the client’s direct access to insert, update, and remove. We are also considering validators and other ORM-like functionality.
Any user having full write access is a pretty big problem for any production app– if a user has write access to your entire database, this is a pretty big security issue.
It’s exciting to see where Meteor (and Derby.js!) is/are headed, but until it matures a little bit, it may not be the best choice for a production application. Hopefully the $11M in funding will go to good use.
To keep up with me, my articles and tutorials, you can follow me on Twitter.
A couple of years ago, I don’t remember being truly baffled by a captcha. In fact, reCAPTCHA was one of the better systems I’d seen. It wasn’t difficult to solve, and it seemed to work when I used it on my own websites.
Fast forward to 2012, and I am trying to log into my Envato Marketplace account on Graphic River. I haven’t been there in a few months, and recently I’ve been working on changing my passwords to be unique-per-site. Understandably, I forgot my password.
But I didn’t entirely forget my password— I knew there are three possible passwords, across two possible usernames. Rather than going through the entire reset password process, which is a hastle and a last resort, I decided to try and guess. After a couple of attempts and failures, I was presented with a reCAPTCHA.
Normally I don’t have an issue with this— after all, I am guessing a password to a user, and I applaud Envato for trying to protect my account. But this time, I couldn’t read the captcha.
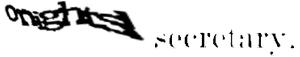
While the word “secretary” is perfectly visible, albeit faded, the first word is more of a puzzle. “Onightsl”? “Onighisl”? Are those even words?
It’s important to note the way reCAPTCHA works. Each user (or bot) is presented with a control word, and a word unrecognized by OCR. This control word is already known to Google (who runs reCAPTCHA). If you get this first word right, it is assumed that you get the second word correct as well. So, in reality, you only need to guess the key word correctly.
I decided to just guess the first word and hope “secretary” was the control. It wasn’t.
Now, not only did I not know if the password I entered was correct or not, I had to resolve another captcha.
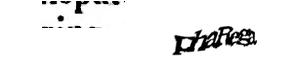
Wonderful. This was near impossible to solve, and instead of wasting my time, I hit the refresh button on reCAPTCHA to get a new image.
Seriously, I am now wasting my time. Refresh.
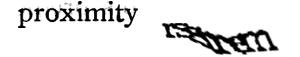
Ok, so this is a little bit better. “Proximity” and… “rsgsrem”? Or was that “rsgmem”? Refresh.
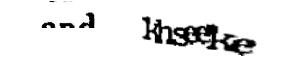
Another cut off word. “and”? Possibly. Refresh.

You can see where this was heading.
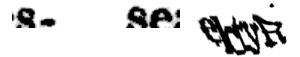


Again, and again, and again. The capatchas were not only difficult for a computer to read, but impossible for a human.
The problem is, computers are getting better at guessing captchas.
In August of 2010, Chad Houck presented at DEF CON 18 with a system that beat reCAPTCHA’s visual system 10% of the time. Google modified their system prior to Houck’s presentation, but it was quickly defeated by Houck who described the modified system as “easier” to crack.
The audio capatcha system is even worse— in May 2012, Adam, C-P and Jeffball presented at LayerOne (a hacker conference) showing a program that beat Google’s audio system 99.1% of the time.
In our attempt to distinguish humans from bots, we have only proved that bots can be just as human as we are— at least when it comes to solving these captchas.
I ended up resetting my password.
I’m working on a new project for iOS, and instead of using Objective-C, I decided to use Appcelerator Titanium again to help speed up development— even though I said I would never use it again.
A long time ago (in the iPad 1 days), I used Appcelerator to build an app called LOL. The problem was, there was a huge memory leak caused by a bug in the framework. Images were not properly released, resulting in a pile up of memory. This was a huge issue because of the 256mb of RAM the iPad 1 had. I published the app after fixing some of the bugs in the framework myself, but there were still issues. I ended up rewriting the entire app natively in Objective-C.
Some two years later, I am back to iOS development. While I did work on a Mac OS X app between “LOL” and now, my Objective-C is rusty, and a lot has changed in the newest versions of iOS. Automatic reference counting (ARC) now solves my worst nightmare for me. Rather than relearn Objective-C, I opted to once again use Appcelerator.
While the memory leak present in the 1.x versions of the framework is long gone, I still find that using Appcelerator is a hassle— especially when debugging. I get useless error messages, like Parse error: unknown file. What does that mean, and what is this “unknown file”?
Logically, I checked to see if I had started referencing any new files since I last built the app. I had— I added a new module to the project. As far as I knew, I had added it correctly.
Next, I did some Googling, until I found this article. Someone mentioned that this error sometimes occurs when there is a syntax error. If this were true, the first part of the error makes perfect sense— there was a problem parsing something because I had a syntax error. But “unknown file”? Really? That isn’t even close, or helpful in solving the problem.
Appcelerator really needs to fix their error messages and show a line number, as well as a more descriptive message. Not one that describes the problem from the framework’s point of view, but from the developer’s.
One reason I wanted to have a Raspberry Pi was to be able to cheaply run periodic scripts and monitoring apps. I could have easily left on a full PC and hid it in my closet, or I could have rented out another Amazon EC2 server, but in both cases, it’s quite expensive. With the dedicated PC, there is a significant up front cost, and depending on the power efficiency of the computer, it could cost me monthly as well in the form of an electricity bill. Amazon EC2, on the other hand, costs anywhere from $20 up to hundreds of dollars a month, which is fine if you need the full power of a server to run a website, but not ok for hacking together some stuff.
With the Raspberry Pi, I have a low cost ($35) and low power device that I can always leave on, without worrying about heat building up in a case or a large power bill— after all, the entire thing runs on a Micro USB port.
Node.js
I’ve been a big fan of Node.js since fall of last year. The first project I really used Node in was a ticketing website for a business competition. There were, however, a few downfalls to using an experimental platform:
- New versions often broke my application, which happened to use Express.js
- Express.js was upgraded from 2.0 to 3.0 in the time I was working on the app— which broke more stuff
- Keeping the app running properly. Unlike PHP and Apache, I had to worry about keeping the script running at all times
However, Node.js is extremely easy to use, and with a helper like Express.js, you can do a lot of things that would normally require significant work in Apache and PHP (.htaccess files and mod_rewrite, for whatever reason, never seem to agree with me). It’s also really fast for me to write— Javascript is my primary development language.
To get Node.js running on the Pi, I had to compile it— it’s only available officially in x86 binaries, as far as I know. These instructions are what got me started. Of course, since I wasn’t using ARM Arch, so I couldn’t simply cheat and use the pre-built version:
$ pacman -S nodejsAfter modifying the files in the V8 engine and setting it to build for Arm, make took over an hour— I left it overnight so I wouldn’t have to watch it build. And because it’s a fan-less machine, it didn’t even disturb my sleep.
Zombie.js
Until recently, to do any parsing of web pages, I’ve used JQuery or regular expressions.
The benefit of using JQuery and the Sizzle CSS selector engine built into JQuery is that I can do the following to get the title of the page:
var doc = $([some html]);
var title = $(doc).find('title').text();
Regular expressions are a little tougher to write and require a bit of testing, but they also let you extract a small part of an HTML element without an issue, and they don’t require the use of a DOM, since all you ever deal with is plain text.
Zombie.js is generally used for virtual browser automation and testing— you can tell it to go to a link, click buttons, and fill out forms. You can also extract values from elements using the same Sizzle engine JQuery uses, making Zombie a great choice for extracting values from HTML as well. And of course, all of this is done from Node.js in a virtual web browser.
Weather Zombie
To test Zombie and Node.js out on the Raspberry, I created a simple script that fetches the forecast for the day at 6 AM on weekdays and 9 AM on weekends, as well as the next day’s weather at 8 PM every night. This data is pushed to my phone using Boxcar, so by the time I wake up, I have the forecast and chance of rain sitting right there. Yes, my iPhone is jailbroken and I could have a weather widget or Intelliscreen X on my lock screen, but this solution will work throughout iOS 6 as well, and it’s a great introduction to using Boxcar’s API.
Rather than starting from scratch, I tried to use an existing Node.js module, but for whatever reason, I could not get it to work. Sending a notification from the API just didn’t seem to get through.
Boxcar’s API is simple enough, so I coded the notification myself. Instead of dealing with Node’s HTTP API, I instead use a module called Restler. With a simple POST request to Boxcar, a push notification is sent to my phone.
However, it is important to remember, if you get a 401 error from the API, you need to subscribe a user to your Boxcar service.
Because I am running into a bug with Zombie.js, I can’t actually parse Weather.com or AccuWeather with it. My local news station works fine, however, and the weather is more accurate anyways. I simply fetch an element that holds the temperature or forecast on the page, and put it in a message to be sent using Boxcar.
All of this is deployed to the Raspberry using Git.
Future Projects
With college coming up in the fall, I’ve been registering for classes and housing. The college dashboard has a ton of information on it, including tuition balances, meal card information, and more, but who wants to log in and look? The next step is to create a script using Zombie.js on the Raspberry to monitor the account balances, and send me a push notification when anything is running low or if there are any significant changes in the notices section. This was actually the idea that allowed me to find Zombie— there is no API, and I have to log into the dashboard somehow.
I've been running my Raspberry Pi on a really old 2GB SanDisk Ultra SD card. It worked fine, but it wasn't fast, and there certainly wasn't that much free space to do anything on. After installing a bunch of packages, compiling Node.js, and cloning a couple of Git repositories, I ran out of space.
I had a Transcend 4GB SD card lying around, and wanted to transfer the entire contents of the older SD card to the larger one.
Cloning the Old Card
I used the same tool that I originally used to write the Debian image to the SD card: Win32DiskImager.
For whatever reason, after inserting the old 2GB card into my computer, typing in a file name for the image, and hitting "read," I got an error that said that the image didn't exist. Well, duh. I was trying to create a new image.
Copying and pasting the Debian .img and selecting it seemed to work. It just got overwritten, as expected.
I popped out the old card, inserted the new 4GB SD, and wrote the image to the card. It worked without any issues.
After plugging the new 4GB SD into the Raspberry and turning it on, I waited for it to boot and tried to SSH and VNC into it-- both actively refused connection. Weird.
Thinking something went wrong during the write, I plugged the Raspberry into the TV again to see if it was outputting errors. Nothing.
After plugging the Raspberry back into the Ethernet and power in my room (it's headless, so no monitor), I could SSH and VNC into it with no problem. Whatever the issue was seemed to solve itself...
Repartitioning the Card
Obviously, because the new 4GB card was an exact clone of the old one, the partitions were still sized for the 2GB card. This meant I gained no free space.
After going to this page and following the directions, I managed to resize the partitions to the full 4GB card-- I now have a little over 2GB of free space, which is expected, since Debian Squeeze uses a little under 2GB.
Wondering how to install the Raspbian operating system on your Raspberry Pi? I've created a guide for that as well.
After receiving my Raspberry Pi, I began to look for a place to plug it into. I've always assumed that at least one of my two monitors sitting on my desk had an HDMI port, but I've always used DVI. I happened to be wrong-- neither of them had HDMI, meaning I had to commandeer a television somewhere else in my house.
I plugged the device into a 55" TV in my living room and booted it up with a 2GB SD card I had prepared earlier and began installing some things that would allow me to run the device headless. This is important, because I do not want to be forced to sit on the floor in front of the TV every time I want to use the Raspberry.
Setting Up TightVNCServer
Because I don't currently have a real monitor to hook up the computer to, I had to find a way to use it without being physically attached to a screen. Naturally, VNC is the perfect tool for the job.
I simply installed TightVNCServer using APT and configured it quickly:
root@raspberrypi: ~# apt-get install tightvncserver
root@raspberrypi: ~# tightvncserver :1
After initializing for the first time, I killed the server to do some configuration:
root@raspberrypi: ~# tightvncserver -kill :1
I added the VNC start command to the /etc/rc.local file to run the VNC server at boot:
echo "Starting VNC server on port 5901"
sudo -u pi tightvncserver :1
This simply starts a VNC server on screen one, which is port 5901. If you were to use screen two, the port would be 5902, and so on and so forth.
The issue was, now that I had the VNC server running, how would I connect to it? There wasn't an easy way to get the IP address of the Raspberry without using ifconfig, but that required a monitor connected to the device to see the output.
An easy way to always know the IP address of the device is to simply set a static IP instead of DHCP allocating one for me. Because my router assigns IP addresses from 192.168.1.100 to 192.168.1.149, I assigned the Raspberry an IP address of 192.168.1.222.
You can do this in Debian Squeeze on the Raspberry by modifying the /etc/network/interfaces file.
I removed the original iface eth0 line and replaced it with the following:
iface eth0 inet static
address 192.168.1.222
netmask 255.255.255.0
gateway 192.168.1.1
I shut down the Raspberry, disconnected it from my TV, and moved it to a more permanent home-- my desk in my room, which happens to be right next to my wireless router (for Ethernet).

Yes, it is an old wireless router.
After waiting for it to boot, I VNC-ed into it, and it works perfectly! I just ordered a HDMI to DVI cable on Amazon for $0.83 so I can do more graphically intense things with the Raspberry without it lagging over the network-- we'll see how that works...
On my PC, I just use TightVNCViewer. On my Macbook Pro, the default screen sharing app works great.
After getting this setup, I compiled Node.js and let it sit overnight-- it took over an hour.

The next step is to find or build a case...
Today the Windows Phone and Silverlight teams at Microsoft released an update to the Silverlight Toolkit. The toolkit is an open source collection of controls that Windows Phone 7 developers can use in their applications. In addition, the kit is localized into all 21 languages supported by WP7 “Mango.”
The Windows Phone Developer Blog has a complete list of the new controls:
LongListSelector has been rebuilt and redesigned to take advantage of the new smooth scrolling and off-thread touch input support in ‘Mango’. This is a buttery-smooth control for showing lists, including grouping and jump list support.
MultiselectList control enables multiple selection for easily working with lists of data, similar to the Mail app’s capability.
LockablePivot adds a special mode to the Pivot control where only the current item is shown (often used with multiple selection).
ExpanderView is a primitive items control that can be used for expanding and collapsing items (like the threaded views in the Mail app).
HubTile lets you add beautiful, informative, animated tiles to your application, similar to the new People groups in ‘Mango’.
ContextMenu control has been reworked: performance improvements and visual consistency fixes.
ListPicker now supports multiple selection.
RecurringDaysPicker lets your users select a day of the week.
Date & Time Converters localized to 22 languages. The converters let developers easily display date and time in the user interface in one of the many styles found throughout the phone’s UI, from a short date like ‘7/19’ to relative times like ‘about a month ago’.
Page Transitions have improved performance for a more responsive feel.
PhoneTextBox is an early look at an enhanced text box with action icon support, watermarking, etc.
All error messages and interface elements have been localized to all of the supported languages, making for a great experience for users around the world.
PhoneTextBox
Among these new controls and features is the PhoneTextBox, an addition developed by me during my internship at Microsoft this summer. This simple control adds a lot of new functionality to the Silverlight TextBox and is really easy to use.
To use it in your app, make sure that the toolkit is referenced in your application and that you have added the XML Namespace in your XAML. If you are already using the Toolkit in your app you won’t have to do this again.
After that’s done, you can simply replace any existing references of the Silverlight TextBox with the PhoneTextBox. For example:
<toolkit:PhoneTextBox Text="Hello World!" />Hint Text
One of the three new features in the PhoneTextBox is "Hint Text." It's kind of like the Placeholder in HTML5. While the WP7 Developer Documentation states that there is a Watermark attribute to the TextBox, it was never implemented and is a dead end. The PhoneTextBox implements this feature by adding a couple of new properties:
Hint- A string that will be displayed in the text box when there is no Text and the control is not in focus.
HintStyle- This allows you to customize the style of the Hint.
Action Icon
The second feature of the PhoneTextBox is called the "Action Icon," a small, 26 by 26 pixel icon that sits in the (bottom) right hand corner. Developers can attach events to the icon that will be called when the icon is tapped.
ActionIcon- An ImageSource that will be displayed on the right side of the control. If the text box is multiline or supports wrapping, it will be shown in the bottom right.
ActionIconTapped- An event that is called when the action icon is tapped. The control will not get focus or open the keyboard when the icon is tapped.
Length Indicator
Lastly, there is a length indicator built into the PhoneTextBox that can prevent users from entering more than a certain number of characters, but provide feedback as to how many characters they have already input.
This feature is more complex and flexible because it has a few different "modes" of operation. First, a developer can simply set a MaxLength and set the LengthIndicatorVisibility to true. The length indicator will always be visible and will display the number of characters entered into the text box out of the MaxLength. (ie. 125/140)
Secondly, a developer can set a LengthIndicatorThreshold. This property determines after how many characters the length indicator should pop down. For example, if the threshold is 20, the length indicator will be hidden if there are 18 characters in the text box. However, once 20 characters have been entered into the text box the length indicator will slide down.
Third, a "soft limit" can be imposed on the text box. In this case, a developer does not set a MaxLength, but rather sets a DisplayedMaxLength. In this scenario, the user can enter more than DisplayedMaxLength characters, much like how the Messaging app behaves in "Mango" for text messages.
LengthIndicatorVisibility- A boolean that determines whether the length indicator is visible or not.
LengthIndicatorThreshold- An integer that determines when the length indicator hides or slides down. Note that LengthIndicatorVisibility must be set to true if you ever want the length indicator to be shown.
DisplayedMaxLength- An integer that overrides the default behavior of showing the format N/MaxLength, where N is the number of characters entered. If DisplayedMaxLength is set, the format will be N/DisplayedMaxLength.
You can also check out the sample app included with the Toolkit to see how you can mix and match these different components.
This is a great new update to the Silverlight Toolkit and I am excited to be a part of this release. If you have any feedback, feel free to use the Issue Tracker on CodePlex.
P.S. If you are using the PhoneTextBox in your app, I'd love to hear from you!